%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Video processing
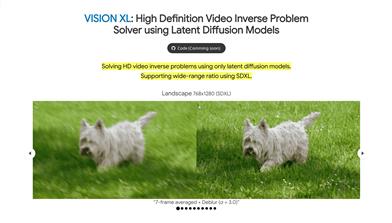
VISION XL
VISION XL is a framework that addresses high-definition video inverse problems using potential diffusion models. It optimizes video processing efficiency and time through a pseudo-batch consistency sampling strategy and batch consistency inversion methods, supporting multiple scales and high-resolution reconstructions. Key advantages of this technology include support for multi-scale and high-resolution reconstruction, memory and sampling time efficiency, and the use of the open-source potential diffusion model SDXL. By integrating SDXL, it achieves state-of-the-art video reconstruction across various spatio-temporal inverse problems, including complex frame averaging and combinations of spatial degradations such as deblurring, super-resolution, and restoration.
Video Production
260.3K
Fresh Picks
SAM 2
Meta Segment Anything Model 2 (SAM 2) is a next-generation model developed by Meta for real-time, promptable object segmentation in videos and images. It achieves state-of-the-art performance and supports zero-shot generalization, allowing it to be applied to previously unseen visual content without needing custom adaptation. The release of SAM 2 follows an open science approach, with code and model weights shared under the Apache 2.0 license, and the SA-V dataset shared under the CC BY 4.0 license.
AI image detection and recognition
58.2K
Llava NeXT
LLaVA-NeXT is a large multimodal model that handles multi-image, video, 3D, and single-image data through a unified interleaved data format, demonstrating its joint training abilities across different visual data modalities. The model has achieved leading results in multi-image benchmarks and has increased the performance or maintained performance of previous stand-alone tasks through appropriate data mixing in various scenarios.
AI Model
72.0K

Morphcut
This product offers a novel framework for smoothing jump cuts, especially in dialogue videos. It leverages the appearance of the subject in the video, using DensePose keypoints and facial landmark-driven intermediate representations to fuse information from other source frames. To achieve motion, it interpolates keypoints and landmarks between surrounding end frames. Then, it uses an image transformation network to synthesize pixels from the keypoints and source frames. Since keypoints may contain errors, a cross-modal attention mechanism is proposed to select and choose the most suitable source for each keypoint. By utilizing this intermediate representation, our method can achieve stronger results compared to strong video interpolation baselines. We demonstrate our method on various jump cuts in dialogue videos, such as removing filler words, pauses, and even random cuts. Our experiments show that we can achieve seamless transitions, even in challenging cases like head rotations or intense movements in dialogue heads.
AI video editing
183.0K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
47.5K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
51.6K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
47.2K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
52.2K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
50.0K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
47.5K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
43.3K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M